Using the methodology given in Guyot et al. BMC Medical Research Methodology 2012, 12:9 (http://www.biomedcentral.com/1471-2288/12/9), we held a practical session to show how to do this in R.
The algorithm in Guyot (2012) is included in the digitise() function in the survHE package.
The first step is to extract the data points from an image by using a plot digitiser app. The plot used to digitise is below. The red points are manual selected along the length of the curve.
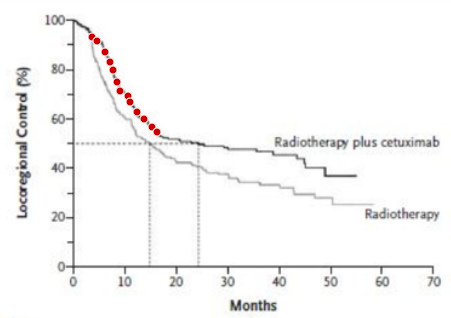
The software uses by Guyot (2012) is called DigitiseIt. In order to use it for the purposes of this tutorial, a fee needs to be paid. Therefore we used a freely available equivalent tool called WebPlotDigitiser. The tools are very similar in functionality. The output of the tools is formated differently however. Also each digitisation may be slightly different simply due to manual selection of points. So we needed to do a little preprocessing before we could use the existing function.
There are 2 matrices required. The survival data taken directly from the Kaplan-Meier plot and the at-risk
matrix which include the row numbers at which the data is divided in to intervals. Read in the data from the digitiser.
Guyot_data <- read.csv("Guyot (2012) data_WebPlotDigitizer2.csv", header = TRUE)
head(Guyot_data)
## Time Survival
## 1 0.0000 1.0000
## 2 0.1722 1.0018
## 3 0.6887 0.9929
## 4 1.2912 0.9821
## 5 2.0660 0.9768
## 6 2.6686 0.9732
Determine which rows the upper and lower values of each interval are.
find_interval_limits <- function(start_time,
surv_time){
if (max(surv_time) > max(start_time))
stop("Intervals must span all survival times. Later interval missing.")
interval <- 1
end_time <- start_time[2]
upper <- NULL
for (i in seq_along(surv_time)){
if (surv_time[i] >= end_time) {
upper[interval] <- i - 1
interval <- interval + 1
end_time <- start_time[interval + 1]
}
}
cbind(lower = c(1, upper + 1),
upper = c(upper, length(surv_time)))
}
interval_limits <-
find_interval_limits(start_time = c(0, 10, 20, 30, 40, 50, 60),
surv_time = Guyot_data$Time)
We can then add these extraction date specific values to the numbers at risk data take from a table in the paper.
Guyot_atrisk <- read.csv("Guyot (2012) at-risk data.csv", header = TRUE)
Guyot_atrisk[, c("lower", "upper")] <- interval_limits
head(Guyot_atrisk)
## Interval time lower upper nrisk
## 1 1 0 1 29 213
## 2 2 10 30 53 122
## 3 3 20 54 68 80
## 4 4 30 69 86 51
## 5 5 40 87 105 30
## 6 6 50 106 111 10
# required row number
Guyot_data <- cbind("k" = rownames(Guyot_data), Guyot_data)
The arguments of digitise are file names of text file so we need to save these data first
write.table(Guyot_atrisk, file = "Guyot_atrisk.txt", row.names = FALS
write.table(Guyot_data, file = "Guyot_data.txt", row.names = FALSE)
digitise(surv_inp = "Guyot_data.txt",
nrisk_inp = "Guyot_atrisk.txt")
IPDdata <- read.table("IPDdata.txt", header = TRUE)
KMdata <- read.table("KMdata.txt", header = TRUE)
head(IPDdata)
## time event arm
## 1 0.6887 1 1
## 2 1.2912 1 1
## 3 1.2912 1 1
## 4 1.2912 1 1
## 5 2.0660 1 1
## 6 2.6686 1 1
head(KMdata)
## time n.risk n.event n.censored
## 1 0.0000 213 0 0
## 2 0.1722 213 0 2
## 3 0.6887 211 1 2
## 4 1.2912 208 3 3
## 5 2.0660 202 1 3
## 6 2.6686 198 1 2
Find the Kaplan-Meier estimates for the recovered data and compare summary statistics with Guyot (2012).
IPD <- as.data.frame(IPDdata)
KM.est <- survfit(Surv(time, event) ~ 1,
data = IPDdata,
type = "kaplan-meier",)
summary(KM.est, times = c(12, 24, 36))
## Call: survfit(formula = Surv(time, event) ~ 1, data = IPDdata, type = "kaplan-meier")
##
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 12 109 65 0.647 0.0355 0.581 0.721
## 24 70 23 0.506 0.0382 0.436 0.586
## 36 39 4 0.468 0.0398 0.396 0.553
survminer::surv_median(KM.est)
## strata median lower upper
## 1 All 25.0502 15.9254 49.1535
We see that the results are very similar to the original survival curve.

Hi! Thanks for this example, but I’m having difficulty understanding how to work the second arm of the data into the matrices that you are inputting into the survfit formula. All I can see from the head(df) is the radiotherapy arm?
LikeLike
Hi Nathan, Thanks for sharing this. I tried to work through this and encountered some errors. I am fairly new to R so pardon the ignorance. The error message said …”number of items to replace is not a multiple of replacement length”. Not sure what this means but do you have a fix you could suggest? thanks
LikeLike